Agriculture Crop Recommendation

Introduction
In this case study, we delve into the development of an Agriculture Crop Recommendation system. The primary objective of this project was to create a solution that aids farmers in making informed decisions about crop selection based on soil and climate data. This case study outlines the challenges encountered during the project, data collection efforts, data preprocessing techniques, model selection, and the integration of the recommendation model into a user-friendly web application.
Client Approach and Needs
The inception of this project began when a prominent agricultural cooperative reached out to our team with a pressing need. Facing the escalating complexities of modern farming, the client sought a data-driven solution to optimize crop selection for their members. They were grappling with inconsistent crop yields and resource allocation due to traditional, experience-based decision-making. Their vision was to harness the power of data science and machine learning to provide personalized crop recommendations to farmers based on their specific soil conditions and local climate patterns. The client's goal was to empower farmers with accurate insights that would not only maximize yields but also promote sustainable farming practices. This need became the driving force behind our Agriculture Crop Recommendation system development, propelling us towards a solution that could transform the agricultural landscape for our client and their community.


Process & Story
Our journey into creating an Agriculture Crop Recommendation system began with a keen awareness of the challenges plaguing modern agriculture. The conventional methods of crop selection, often reliant on experience, led to erratic yields and resource inefficiencies. Recognizing the need for a data-driven solution, our path began to take shape.
The Problem
The main challenge in our Agriculture Crop Recommendation case study was improving how farmers make decisions about what crops to plant. Traditional methods often led to problems like uneven yields and wasted resources, aggravated by changing weather and soil conditions. We needed a solution that used data to suggest the best crops for each farmer's specific conditions. So, the challenge was twofold: developing a data-driven solution and creating a system that seamlessly combined soil and climate data to recommend crops for sustainable and productive farming.
The Challenges
Handling Null Values:
One of the foremost challenges faced in this project was dealing with null values within the dataset. Missing data can significantly affect the accuracy of analysis and model training. The challenge was to strike a balance between retaining valuable data and avoiding potential biases that might arise from imputing missing values. To address this issue, we implemented a two-pronged approach:
Statistical Imputation Methods:
We applied various statistical imputation methods to fill in missing data points.
Machine Learning-Based Imputation:
For more complex data patterns, we employed machine learning-based imputation models to impute missing values.
Imbalanced Data:
Imbalanced data occurs when one class significantly outweighs the others in the dataset. This imbalance can lead to skewed model training and biased predictions. To mitigate this issue, we explored several techniques:
Resampling:
We employed resampling techniques, including oversampling the minority class and undersampling the majority class, to rebalance the dataset.
Class Weight Adjustment:
During model training, we adjusted class weights to give equal importance to all classes. Ensemble Methods: Ensemble methods were used to improve model performance and address imbalanced data challenges.

Solutions
To recommend crops effectively, we experimented with various Machine Learning algorithms, including Logistics Regression, GaussianNB, DecisionTreeClassifier, and RandomForestClassifier. After conducting extensive evaluations, we determined that the RandomForestClassifier produced superior results compared to other algorithms. Testing and Integration: After implementing the model, we rigorously tested its performance using real-world data. Test data was collected from various sources and evaluated against the model's predictions in real-time scenarios. To enhance usability, we integrated the crop recommendation model into a web application, ensuring accessibility and convenience for end-users.
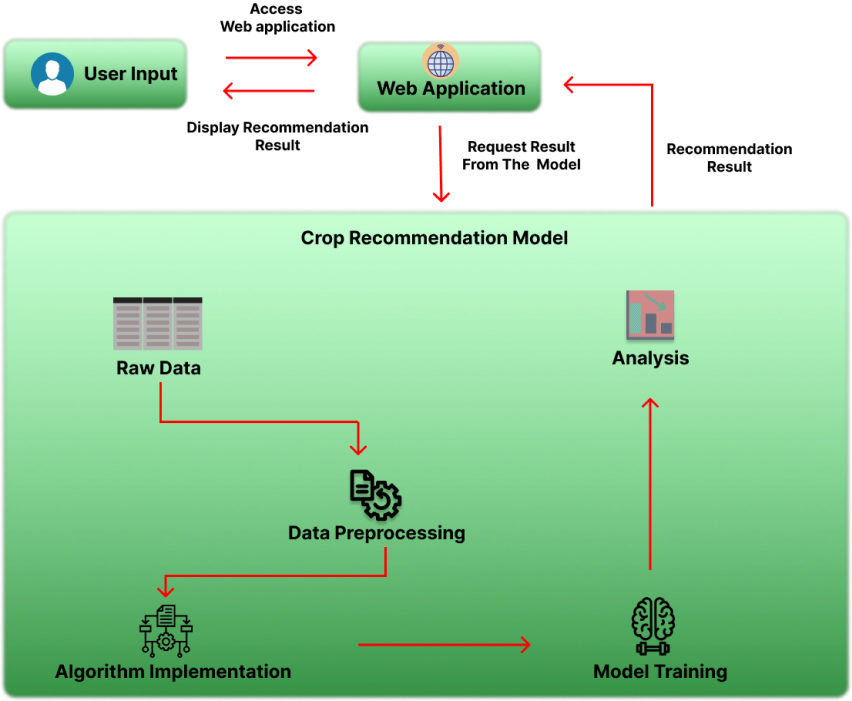

Real-time Testing
In the Agriculture Crop Recommendation case study, the most crucial phase was the real-time testing process. This phase determined whether our system could effectively handle live, real-world data. We input current data from farms into the system and closely monitored its performance. The system provided recommendations confidently, instilling hope and offering valuable insights for farmers in real-time. This phase validated the practicality of our data-driven approach and marked a significant stride towards empowering farmers with actionable information for optimized crop selection and sustainable agriculture practices.
User-Friendly Integration
In our Agriculture Crop Recommendation case study, we focused on user-friendliness by integrating the recommendation system into an easy-to-use web application. Farmers could input their soil and climate data effortlessly, and the system quickly generated personalized crop recommendations. This user-friendly approach simplified complex agricultural insights, empowering farmers to make informed decisions for better crop yields and sustainability.

Tools & Techniques
Deep Learning

Python

Flask

React JS
Conclusion
This case study highlights the challenges encountered and solutions implemented during the development of an Agriculture Crop Recommendation system. The project successfully addressed issues related to null values and imbalanced data, leading to the selection of the RandomForestClassifier as the optimal algorithm. The integration of the recommendation model into a user-friendly web application marked the culmination of this effort, providing valuable support to farmers in making informed crop selection decisions.