IPL Win Match Probability

Introduction
In this case study, we delve into the development of an IPL Match win probability. The main goal of this research was to develop a machine learning model that uses some pre-processed data and predicts which team has the best chance of winning the match. In this case study, the difficulties faced during the project are discussed, along with the methods used to acquire the data, preprocess it, choose a model, and incorporate it into a user-friendly online application.
Client Approach and Needs
The inception of this project began when a prominent sports cooperative reached out to our team with a pressing need. The client needs a user-friendly, web-based application that can estimate the percentage chance that their IPL team will win a game. Numerous variables, such as squad composition, player statistics, pitch conditions, previous match data, and other pertinent characteristics, should be considered by this program. The application should have an intuitive user interface accessible to team managers, coaches, and analysts. It should provide clear visualizations and reports that display the predicted winning percentage and key contributing factors. To ensure accuracy, the application should continuously update its predictions as new data becomes available during a match. It should adjust probabilities based on the evolving match conditions, such as the current run rate, wicket count, and player performance.

Process & Story
Our journey to create an IPL Win Match Probability model started with a big challenge: predicting who would win cricket matches in the fast-paced Indian Premier League (IPL). Cricket is a huge part of India's sports scene, and we wanted to make IPL matches even more thrilling by accurately predicting the winners.
The Problem
The main challenge in our IPL Win Prediction case study was the unpredictability of cricket matches, especially in the Indian Premier League (IPL), known for its dynamic and competitive nature. It was tough to foresee who would win due to the many factors involved. Fans and team decision-makers needed a dependable way to predict match outcomes, and that's where our challenge began – to create a reliable win prediction model for a more exciting IPL experience and better decision-making.
The Challenges
Data Scraping and Collection:
Gathering comprehensive IPL match data, player statistics, and related information from various sources was a time-consuming task. we had to scrape data from numerous websites while ensuring they adhered to ethical and legal data collection practices.
Merging Datasets:
We encountered significant challenges while merging two distinct datasets collected through different methods. The first dataset, obtained traditionally, was well-structured and organized, while the second dataset, gathered through web scraping, consisted of unstructured data from various online sources. The challenge lay in reconciling these differences, including data formats, integration complexities, varying data volumes, and ensuring data quality and privacy compliance. Our team successfully addressed these challenges through meticulous data preprocessing and integration efforts, ultimately benefiting from a more comprehensive dataset that provided valuable insights.
Data Quality:
Datasets from different sources exhibited inconsistencies, errors, and missing values. Standardizing data formats, correcting errors, and handling missing values posed significant challenges. Merging data from multiple sources was challenging due to variations in data structures and formats. Harmonizing these disparate datasets into a consistent format for model training required extensive effort.
Handling Null Values:
Null values in the dataset needed careful treatment. Decisions had to be made regarding whether to remove rows with null values, impute missing data, or apply specialized handling techniques based on the context.
Solutions
Following an extensive evaluation of multiple machine learning models, including the Random Forest Classifier and Decision Tree Classifier, the Logistic Regression Classifier emerged as the most favorable choice for predicting IPL match-winning probabilities. This choice was informed by a comprehensive analysis of model performance metrics, wherein the Logistic Regression Classifier consistently demonstrated an exceptional balance between accuracy, precision, recall, and the F1-score. Its interpretability and transparency, characterized by easily interpretable coefficients, made it particularly appealing, offering stakeholders valuable insights into the factors influencing match outcomes. Additionally, the model's simplicity and ease of implementation ensured robustness and facilitated future updates.
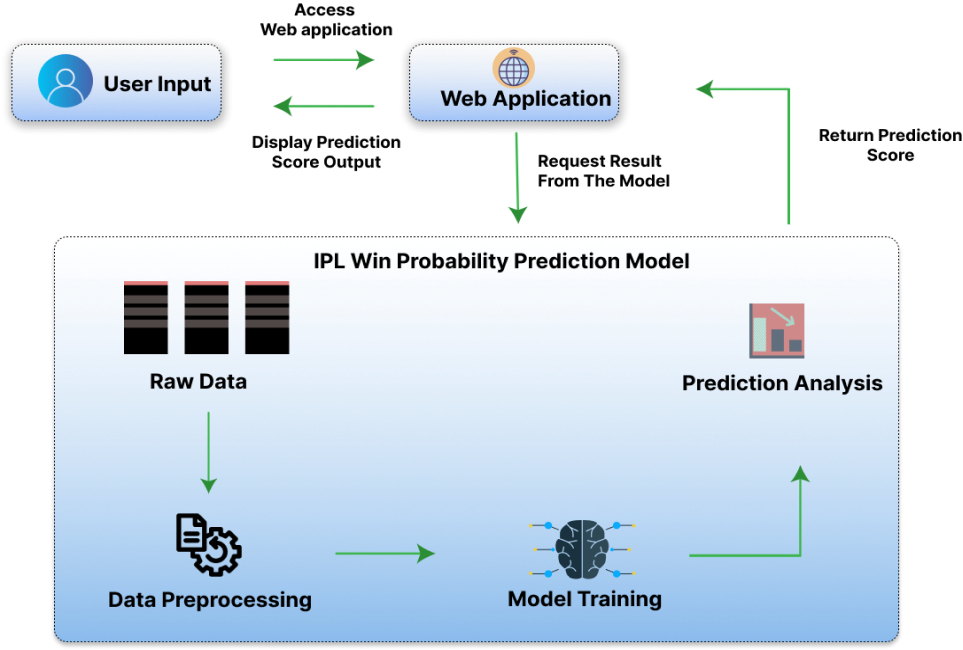

Real-time Testing
In the IPL Win Prediction case study, real-time testing was a critical phase where our prediction model was put to the test during live matches. The model continuously analyzed current match data, including runs, wickets, player performance, and pitch conditions. It provided dynamic updates on win probabilities as the game progressed, offering valuable insights to fans, team managers, and analysts. This real-world testing validated the model's accuracy and its ability to adapt to the changing dynamics of cricket matches, enhancing the IPL experience by providing real-time win probability estimates for better decision-making.
User-Friendly Integration
In our IPL Win Prediction case study, we prioritized user-friendliness by integrating the prediction model into a simple web application. Cricket fans, team managers, and analysts could access match predictions effortlessly. The interface offered clear visuals and real-time updates, making it easy for users to understand and engage with the data. This user-friendly integration enhanced the IPL experience for fans and facilitated informed decisions for teams in a straightforward manner.
Tools & Techniques
Deep Learning

Python

Flask

React JS
Conclusion
The Bangalore House Price Prediction case study demonstrates the intricacies of predicting real estate prices in a dynamic market. Challenges in data collection, null value handling, and location data formatting were overcome using appropriate techniques. The application of Linear Regression, Decision Tree Regression, and Lasso Regression provided insights into different modeling approaches. Finally, Grid Search CV helped identify the most suitable model for accurate house price predictions. This case study serves as a testament to the value of data-driven solutions in the real estate sector, aiding both buyers and sellers in making informed decisions.